Keywords
Altmetric, science communication, media coverage, knowledge dissemination, health research
Altmetric, science communication, media coverage, knowledge dissemination, health research
Scientific publications have grown exponentially in recent years, contributing to an ‘infodemic’ as seen during the Covid-19 pandemic1–3. With around 1.5 million new items being added to PubMed per year, or 2 papers per minute, there is a need to demonstrate impact of the research to ensure that the scientific community is not favouring quantity over quality4. For many years, impact measures were focused on citation counts which are primarily metrics of influence to other academics working in related fields. However, there have been shifts in the past decade away from traditional bibliometrics like citation counts as they can be poor predictors of quality and impact, have a large lag time, and are largely focused on academics5,6. Increasingly researchers, institutions, and funders are considering ‘alternative metrics’ or altmetrics to measure the real-time impacts of research on a broader population7.
Traditional bibliometrics and altmetrics are complementary measures which provide a more complete picture of impact8. Altmetric tracks the immediate online attention given to scientific publications (https://www.altmetric.com/about-us/our-data/how-does-it-work/), making it an invaluable tool in crowded information environments. It provides an ‘Altmetric-mentioned score’ which factors in sources from social media (e.g., Facebook, X), YouTube videos, newspapers, policy documents, Wikipedia, question-and-answer sites (e.g., Stack Overflow), and more. (https://www.altmetric.com/about-us/our-data/our-sources/) Altmetric attention scores have been found to be associated with citation counts7,9 and journal impact factor10 and those articles with higher Altmetric scores (i.e., those promoted online simultaneously) were more likely to be cited in public policy documents11. This attention score has also been shown to be significantly higher for Covid-19 related articles than for non-Covid-19 articles in 202012.
How research findings are presented through domestic news can influence behaviour and risk perceptions13–16. Therefore, it would be beneficial for health researchers and healthcare practitioners to better understand the influence that the dissemination of research publications and their subsequent coverage can have on public behaviour. Analyses of research publication’s online impact can provide insights on effective communication strategies for research outputs produced during COVID-19, for future pandemics, and in generally oversaturated complex information environments17. Despite the shift to online global social media, countries still have their own unique landscape and conditions with varying rates of audience engagement and trust in their local and international news sources18.
According to the 2023 Reuters Digital News report18, Irish consumers have bucked international trends, with levels of trust in news remaining fairly high. Almost half (47%) agreed that they can trust most news most of the time. Ireland can also be consider an outlier in other ways, with 96% of adults having received the full primary COVID-19 vaccination course in 2022, compared to the EU average of 82%19,20 and registering the fourth lowest rate of excess deaths among OECD countries during the Covid-19 pandemic (2020–2022). While the strong uptake of vaccination clearly had an impact, evidence-based public health messaging (e.g., https://ihealthfacts.ie/) and clear messaging in the mainstream media likely also contributed to beneficial behaviour changes21,22.
Ireland has also recently made significant investment in health research and healthcare reforms through its Health Service Executive (HSE) Action Plan for Health Research (2019 – 2029)23 and Sláintecare reform24. The Action Plan emphasizes that dissemination and implementation of research are essential to achieving impactful policy and practices that meet the needs of patients, the health service, and policy makers23. A better understanding of the online impact of recent health research can help researchers, and the communication specialists who help disseminate their work, identify pathways for more effective communication to the public. We aim to map a piece of the complex local landscape of research in Ireland, using a cross-sectional analysis of Altmetric data (2017 – 2023) and see how it has evolved since before, during, and after the Covid-19 pandemic. Innovations and dissemination can be improved through better recognition of changing narratives and key players.
Our primary objective is to analyse the amount and type (i.e., medium) of online attention given to health research produced by Irish organisations in recent years (2017 – 2023). We aim to investigate differences over time to identify changing trends, particularly as the online coverage of health research may have been affected during the Covid-19 pandemic.
Our secondary objective is to identify differences in the amount of coverage between areas (e.g., nutrition vs. neurology) and where possible, study types (clinical trials vs. evidence syntheses).
This project will be a cross-sectional study as it is a snapshot of online attention given to research outputs (i.e., articles, books, and chapters) from one defined time period (2017 – 2023) with the main focus to provide descriptive prevalence insights and changing trajectories of online attention. Project findings will be reported according to the STROBE Statement25
Data for this study will be gathered from Altmetric institutional access. Altmetric (altmetric.com) tracks 4,000 global news outlets, X (formerly Twitter), YouTube, Reddit, Stack Overflow (Q&A), a curated list of public Facebook pages, blogs, public policy documents, IFI CLAIMS patents, Wikipedia, Mendeley, and Publons. It uses a unique identifier (e.g., DOI, PubMedID, arXiv ID, ISBN, etc.) to track online attention given to a specific research output. (https://www.altmetric.com/about-us/our-data/how-does-it-work/) We will use Altmetric to search for all research outputs published between 1 January 2017 and 31 December 2023 from active Irish organisations that have Research Organisation Registry (ROR) IDs. ROR is a global registry of open persistent identifiers for research organisations which helps link researchers and their outputs to institutions across sectors (e.g., education, government, healthcare, non-profit, etc.) (https://ror.org/about/). As of 9 April 2024, there are 641 active research organisations with Ireland listed as their country of address. Altmetric uses the prior system, the Global Research Identifier Database (GRID) (https://www.grid.ac/) which maps to ROR. Datasets are available through Altmetric Explorer as downloadable csv files. The Altmetric API (https://www.altmetric.com/solutions/altmetric-api/) is also available for information retrieval.
Each dataset (e.g., csv file) contains 48 standard columns or variables, one of which is the field of research. Each research output in the dataset is classified to at least one field of research (FoR) using the 2020 Australian and New Zealand Standard Research Classification (ANZSRC) system. The ANZSRC is a hierarchical system which contains divisions (broad subject areas or research disciplines) which are further detailed into subsets: groups and fields. ANZSCR was developed for use in the measurement and analysis of research and experimental development (R&D) statistics in Australia and New Zealand.(19) In instances where there is a lack of information and it cannot be classified at this level, the code is assigned based on a journal-level classification.
For the purposes of our project we are primarily interested in the following Divisions of biomedical research listed in Table 1: Biological Sciences (31), Biomedical and Clinical Sciences (32), Chemical Sciences (34), Health Sciences (42), and Psychology (52). Excluded areas include: Agricultural, Veterinary and Food Sciences (30), Built Environment and Design (33), Commerce, Management, Tourism and Services (35), Creative Arts and Writing (36), Earth Sciences (37), Education (39), Engineering (40), Environmental Sciences (41), History, Heritage and Archaeology (43), Human Society (44), Indigenous Studies (45), Information and Computing Sciences (46), Language, Communication and Culture (46), Law and Legal Studies (48), Mathematical Sciences (49), Philosophy and Religious Studies (50), and Physical Sciences (51). As research outputs can be classified to several areas, as long as at least one of our included Divisions is in the field, the output will be included. For example, if a study is about the health impacts of environmental pollution and contamination, it could be classified under Biomedical and Clinical Sciences (32) and Environmental Sciences (41), thus it would still be retained.
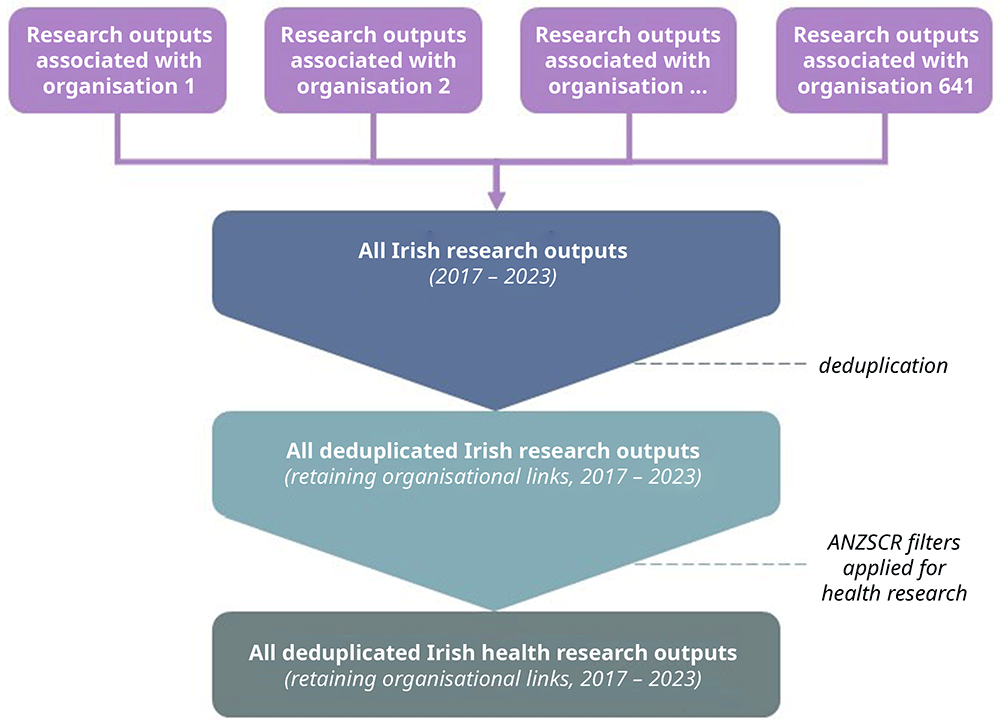
All individual organisation datasets will be stacked and combined, deduplicated, and filtered to only contain research outputs pertaining to at least one field of health research as defined by the ANZSRC. (Figure 1) Each research output, despite having different authors and organisation affiliations, should have the same direct object identifier (DOI). This DOI allows all impact metrics to be linked to the specific research output; therefore, the deduplicated dataset should not lose that data. Of note, author affiliations with a research output do not depend on placement (e.g., first, corresponding) and we will create a new variable to maintain links in the likely case where a research output is associated with multiple organisations. For example, if research output X was published by both author 1 at organisation A and author 2 at organisation B, the research output should contain the same DOI which is the information that is being used to track all the attention, therefore, that information should not change and deduplication does not pose a threat to data loss.
We will use R version 4.3.2 (https://shiny.rstudio.com/) to analyse data for this project. As data will be gathered using an institutional license for Altmetric Explorer, we will use R Markdown (https://rmarkdown.rstudio.com/) to create an html document to maintain privacy of the proprietary data but promote reproducible research practices. The .rmd file will also be available on GitHub (https://github.com/sharpmel) and the project will be registered on the Open Science Framework. (https://osf.io/kfct6/)
Data will be cleaned using R and descriptive analyses will be performed, establishing counts and frequencies of coverage by sector (e.g., government, healthcare, education), academic research institution and clinical area. The deduplicated dataset with unique research outputs will be used for analyses into clinical area, medium (e.g., traditional news, X, etc.), and open access status. All data will be plotted on a daily quarterly, and yearly basis from 1 January 2017 through 31 December 2023. As the World Health Organisation (WHO) declared Covid-19 a pandemic on 11 March 202026 and no longer a public health emergency of international concern on 5 May 202327, we will use these cut points in the data to determine pre-, during, and post- pandemic. Data will also be segmented by the included Divisions of research per year.
Assuming an adequately sized dataset, we will also like to investigate whether Altmetric Attention Scores correlate to traditional article-level citation metrics, we will use Crossref’s metadata, the rcrossref package, and the Crossref API (https://api.crossref.org/) to match outputs by DOI to obtain data to run Pearson’s correlation tests on the data.
Field and clinical area. Although the FoR classification system will give some insights as to content areas which are being covered, it does not provide more granular detail (e.g., clinical conditions), thus we will characterise the research outputs using topic modelling on the Title field of the Altmetric dataset. Topic modelling is a method of unsupervised classification of document which can discover “topics” in the corpus. We will use latent Dirichlet allocation (LDA)28 method to identify the mixture of words associated with each topic and the mixture of topics within the corpus or document.
After cleaning titles to address punctuations, special characters, etc. we will perform tokenization to break down the titles into individual tokens or words. Package-level reference-corpuses from the R package tidytext (https://cran.r-project.org/web/packages/tidytext/index.html) will be used for removing stopwords, or words that to not add any value (e.g., the, an). We will review the output and add additional stop words if necessary. Next, we will perform lemmatization which structurally transforms the token or word to its meaningful base form, or lemma. For example, treating, treats, and treated would all be changed to treat. The process to prepare the titles for topic modelling is shown in Figure 2.

Using the textmineR package (https://cran.r-project.org/web/packages/textmineR/), we will then set the optimal number of topics (e.g., a minimum of 5 and a maximum of 57 as a preliminary guide from the ANZSCR classifications). We will choose the number of our final topic number based on the highest coherence score and a review of the balance between too narrow and too broad in comparison with the ANZSCR classifications. If necessary, we will explore more than 57 topics. Frequency polygons will be generated using ggplot2 (https://ggplot2.tidyverse.org/) to plot topic frequency from 01 January 2017 to 31 December 2023. We may also explore this approach using the abstract of research outputs from the CrossRef dataset as the data may be richer.
Study design. Given an appropriate size of the dataset, we will first use the metadata available in Crossref dataset to pull the research output’s abstract and author keywords which will then undergo classification. We will create a list of key terms, in consultation with our project’s steering committee and medical librarians and to classify research outputs within the umbrella categories of: intervention studies (e.g., trials), observational studies (cohort, cross-sectional, case control, genetic association, DTA, etc.), qualitative research (focus groups, interviews), protocols, case reports, evidence syntheses (e.g., systematic and scoping reviews), editorials or opinions, and other. These likely will be linked to the stopwords created during topic modelling. At least one reviewer will check the classifications after review.
Limitations. Our main limitation is the dataset itself and the quantitative focus of measuring impact. Firstly, Altmetric does not track certain platforms such as LinkedIn, TikTok, and Instagram, thus its generalisability is diminished. It has also been reported to have issues tracking publications with multiple versions (i.e., a pre- and post-print) and the replication of the data can sometimes be difficult due to constantly changing access agreements with data providers29. Furthermore, although higher scores can be expected from newer papers as time since publication has shown to be associated with Altmetric scores10, even running searches one month apart resulted in changing numbers as old articles can be brought up for discussion at any time. We will try to address this by pulling the data in a discrete period of time and we have included a time buffer (i.e., the end of 2023).
The quantitative focus of the metrics in the dataset can also lose the context of the coverage and does not account for ‘dose’, i.e., where a mention may be an extensive discussion or extremely brief. Providing a broad overview of the online attention given to health research in Ireland in recent years is our primary objective. Our datasets are not meant for social listening purposes and audience metrics may be limited. However, our project’s results may provide a basis to build upon for future studies investigating how the media is actually covering the work. Altmetric may also be a flawed metric of impact on the public as previous research has shown that most tweets came from within academia with other academics interacting with them30. Notably, the data in our project likely will contain more health research produced from the academic sector as they primarily communicate via articles, books, and chapters, however, we have included pharmaceutical agencies, governmental health bodies, and hospitals (where they have an ROR) which may provide a broader overview of the online coverage of health research in Ireland. A recent bibliometric analysis of HRB supported publications31 found the academic sector well-represented although our project is much broader in its scope. Lastly, our last aim focused on study designs is exploratory in that, to our knowledge, there is no best approach for text mining classification study designs32 and most approaches have focused on classifying trials to expedite the systematic review process33,34. Research using PubMed’s ‘article type’ classification highlighted its oversimplified classification system wherein review, systematic review, and trials are the only publication type options, likely contributing to much missing data4.
A better understanding of the amount and type of online attention given to health research produced by Irish organisations in recent years can identify changing trends and gaps in attention. By looking at organisation-linked data and unique research outputs, we can provide insights to researchers and organisations (particularly universities) looking to evaluate the impact of their work and identify the strengths and weaknesses of their research portfolios. Results may be particularly useful for researchers and communication specialists who are aiming disseminate their research to the public and find ‘airtime’ in a particularly noisy information environment. Our use of open source coding also will offer a reproducible workflow for future monitoring and further investigations into the content of the health research coverage itself. Overall, the project should provide us with a piece of the puzzle of the landscape of online attention given to health research in Ireland.
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Register with HRB Open Research
Already registered? Sign in
Submission to HRB Open Research is open to all HRB grantholders or people working on a HRB-funded/co-funded grant on or since 1 January 2017. Sign up for information about developments, publishing and publications from HRB Open Research.
We'll keep you updated on any major new updates to HRB Open Research
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)